# HAZARD RATIOS (log-normal distribution)
hr_os_mean <- log(0.70) # Log mean
hr_os_sd <- 0.15 # Log SD
hr_pfs_mean <- log(0.50)
hr_pfs_sd <- 0.20
# COSTS (gamma distribution)
cost_pf_trast_yr1_mean <- 420000
cost_pf_trast_yr1_sd <- 80000 # ~19% of mean
cost_pd_mean <- 180000
cost_pd_sd <- 40000 # ~22% of mean
# UTILITIES (beta distribution)
utility_pf_mean <- 0.80
utility_pf_sd <- 0.05
utility_pd_mean <- 0.55
utility_pd_sd <- 0.08PSA for the Partitioned Survival Model
Quantifying uncertainty in the trastuzumab cost-effectiveness analysis
PSA Results: ICER Distribution
Code
library(ggplot2)
# Simulated PSA ICER results (for illustration)
set.seed(42)
icer_dist <- rgamma(3000, shape = 40, rate = 0.00028)
icer_dist <- icer_dist[icer_dist > 50000 & icer_dist < 500000]
ggplot(data.frame(ICER = icer_dist), aes(x = ICER)) +
geom_histogram(bins = 50, fill = "#3498db", colour = "white", alpha = 0.8) +
geom_vline(xintercept = 170000, colour = "red", linetype = "dashed", linewidth = 1.2) +
annotate("text", x = 170000, y = Inf, label = "WTP = ₹1,70,000/QALY",
colour = "red", hjust = -0.05, vjust = 2, size = 3.5) +
scale_x_continuous(labels = function(x) paste0("₹", format(round(x/1000), big.mark=","), "K")) +
labs(x = "ICER (₹/QALY)", y = "Frequency",
title = "Distribution of ICER: Trastuzumab vs Chemo Alone",
subtitle = "3,000 PSA iterations") +
theme_minimal()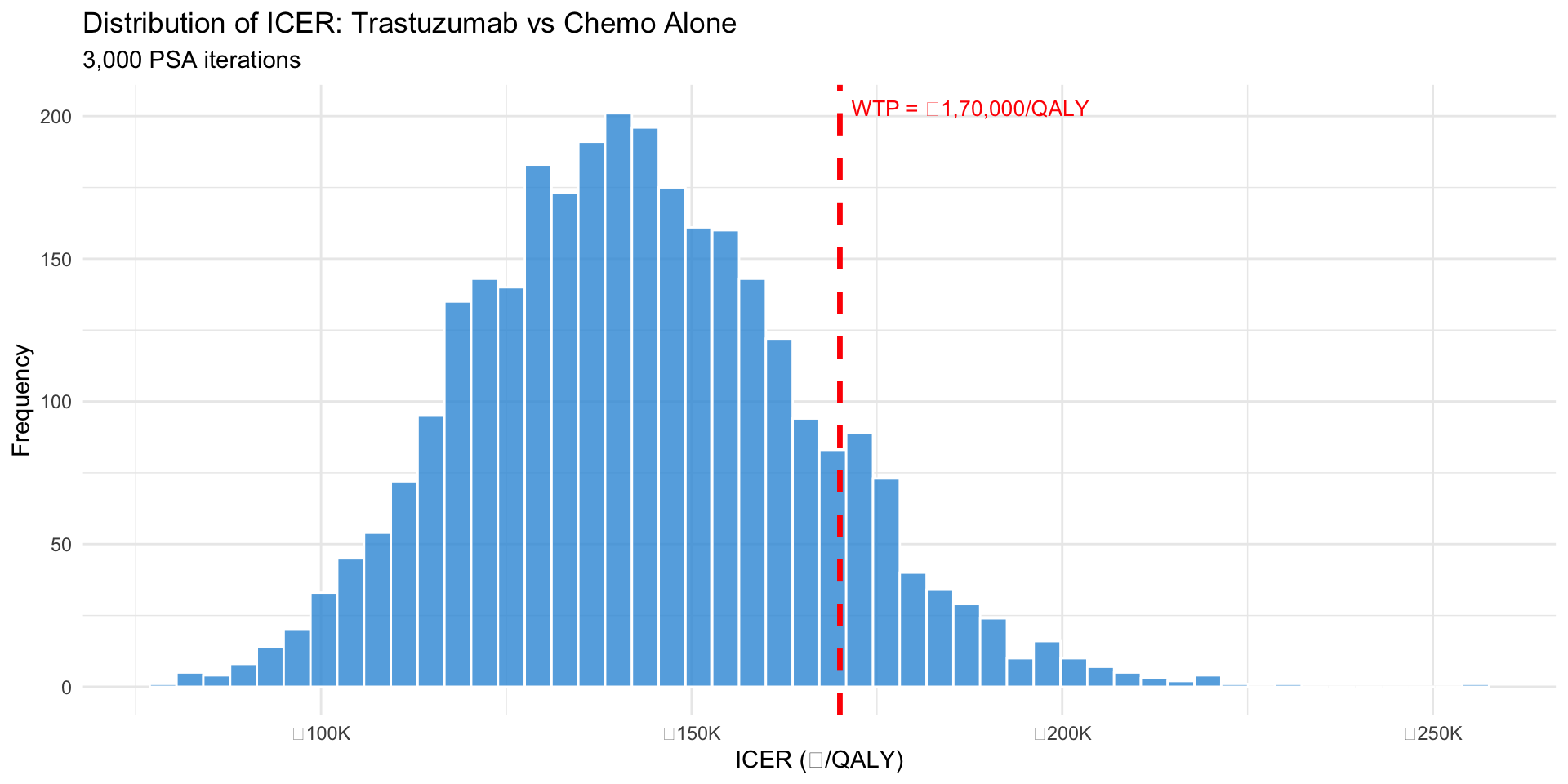
Figure 1: 3,000 PSA iterations of ICER estimates
Key findings: - Mean ICER: ~₹1,65,000/QALY - 95% CrI: [₹1,10,000, ₹2,40,000] - Wide range reflects parameter uncertainty
Cost-Effectiveness Plane
Code
# Simulated CE plane data
set.seed(42)
n <- 3000
inc_qaly <- rnorm(n, 2.5, 0.8)
inc_cost <- inc_qaly * 1.65e5 + rnorm(n, 0, 2e5)
ce_at_threshold <- inc_cost <= 170000 * inc_qaly
ce_data <- data.frame(inc_qaly, inc_cost, ce_at_threshold)
ggplot(ce_data, aes(x = inc_qaly, y = inc_cost, colour = ce_at_threshold)) +
geom_point(alpha = 0.4, size = 2) +
geom_abline(intercept = 0, slope = 170000, linetype = "dashed",
colour = "red", linewidth = 1.2) +
annotate("text", x = 3.5, y = 450000, label = "WTP threshold\n₹1,70,000/QALY",
colour = "red", size = 3.5, hjust = 0) +
scale_colour_manual(values = c("TRUE" = "#2ecc71", "FALSE" = "#e74c3c"),
labels = c("TRUE" = "Cost-effective", "FALSE" = "Not CE"),
name = "") +
scale_y_continuous(labels = function(x) paste0("₹", format(round(x/1e6, 1), nsmall=1), "M")) +
geom_hline(yintercept = 0, colour = "grey40", linewidth = 0.4) +
geom_vline(xintercept = 0, colour = "grey40", linewidth = 0.4) +
annotate("text", x = 4, y = -3e5, label = "DOMINANT\n(cheaper + better)",
colour = "#2ecc71", size = 3, fontface = "bold") +
annotate("text", x = -0.5, y = 6e5, label = "DOMINATED",
colour = "#e74c3c", size = 3, fontface = "bold") +
labs(x = "Incremental QALYs", y = "Incremental Cost (₹)",
title = "CE Plane — 4 Quadrants",
caption = "Each point = one PSA iteration") +
theme_minimal() +
theme(legend.position = "bottom")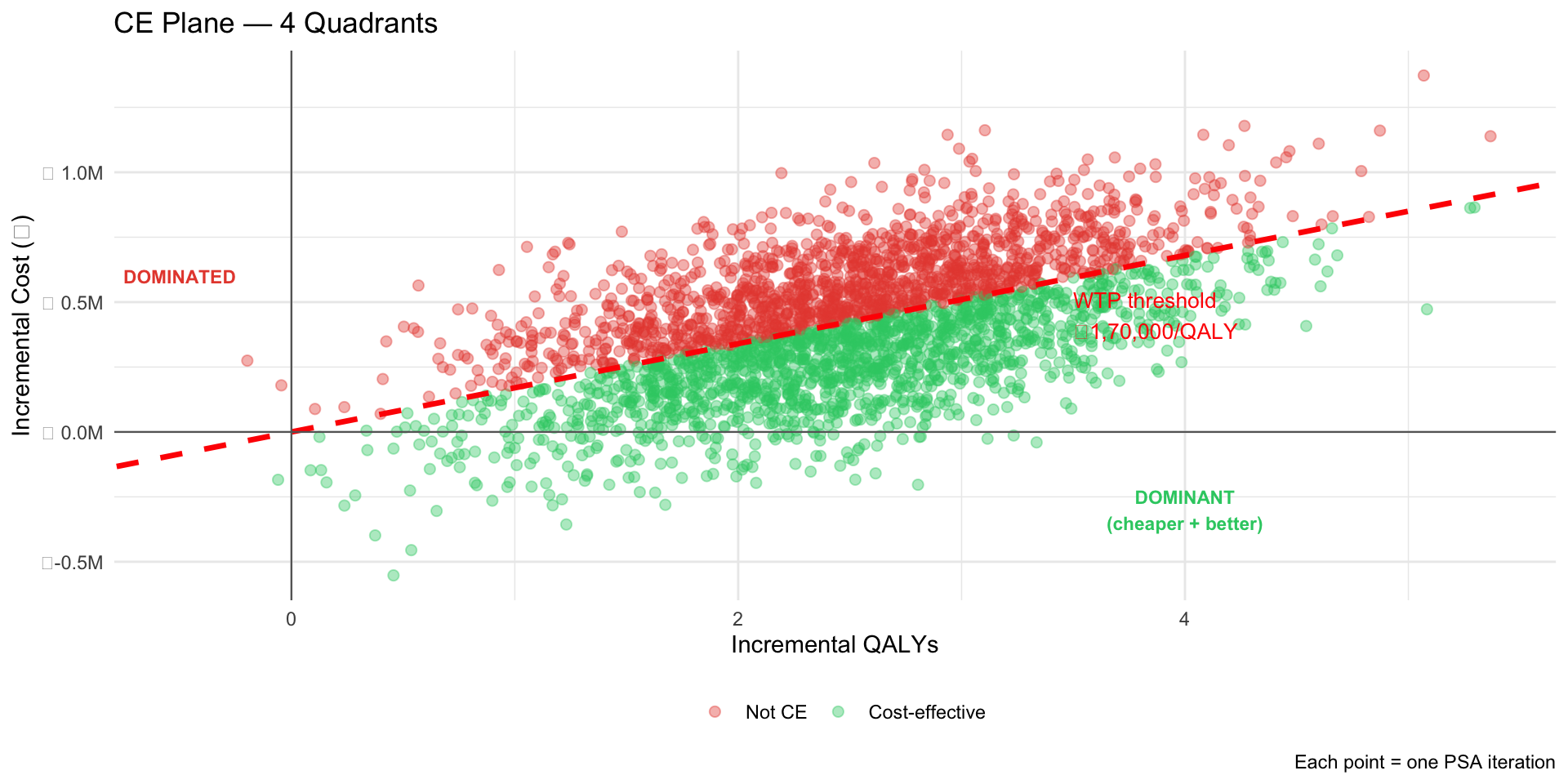
Figure 2: Each point: one PSA iteration
Cost-Effectiveness Acceptability Curve (CEAC)
Code
# Simulate CEAC
wtp_range <- seq(0, 400000, by = 5000)
ce_prob <- sapply(wtp_range, function(wtp) {
mean(inc_cost <= (wtp * inc_qaly))
})
ceac_df <- data.frame(wtp = wtp_range, prob_ce = ce_prob)
ggplot(ceac_df, aes(x = wtp, y = prob_ce)) +
geom_line(linewidth = 1.3, colour = "#3498db") +
geom_ribbon(aes(ymin = 0, ymax = prob_ce), alpha = 0.2, fill = "#3498db") +
geom_vline(xintercept = 170000, linetype = "dashed", colour = "red", linewidth = 1) +
geom_hline(yintercept = 0.5, linetype = "dotted", colour = "grey", linewidth = 0.8) +
annotate("text", x = 170000, y = 0.92, label = "WTP =\n₹1,70,000",
hjust = 0.5, size = 3.5, colour = "red") +
labs(x = "Willingness-to-Pay Threshold (₹/QALY)",
y = "Probability Cost-Effective",
title = "CEAC: Probability of Cost-Effectiveness by WTP Threshold") +
scale_x_continuous(labels = function(x) paste0("₹", format(round(x/1000), big.mark=","), "K")) +
scale_y_continuous(limits = c(0, 1), labels = scales::percent) +
theme_minimal()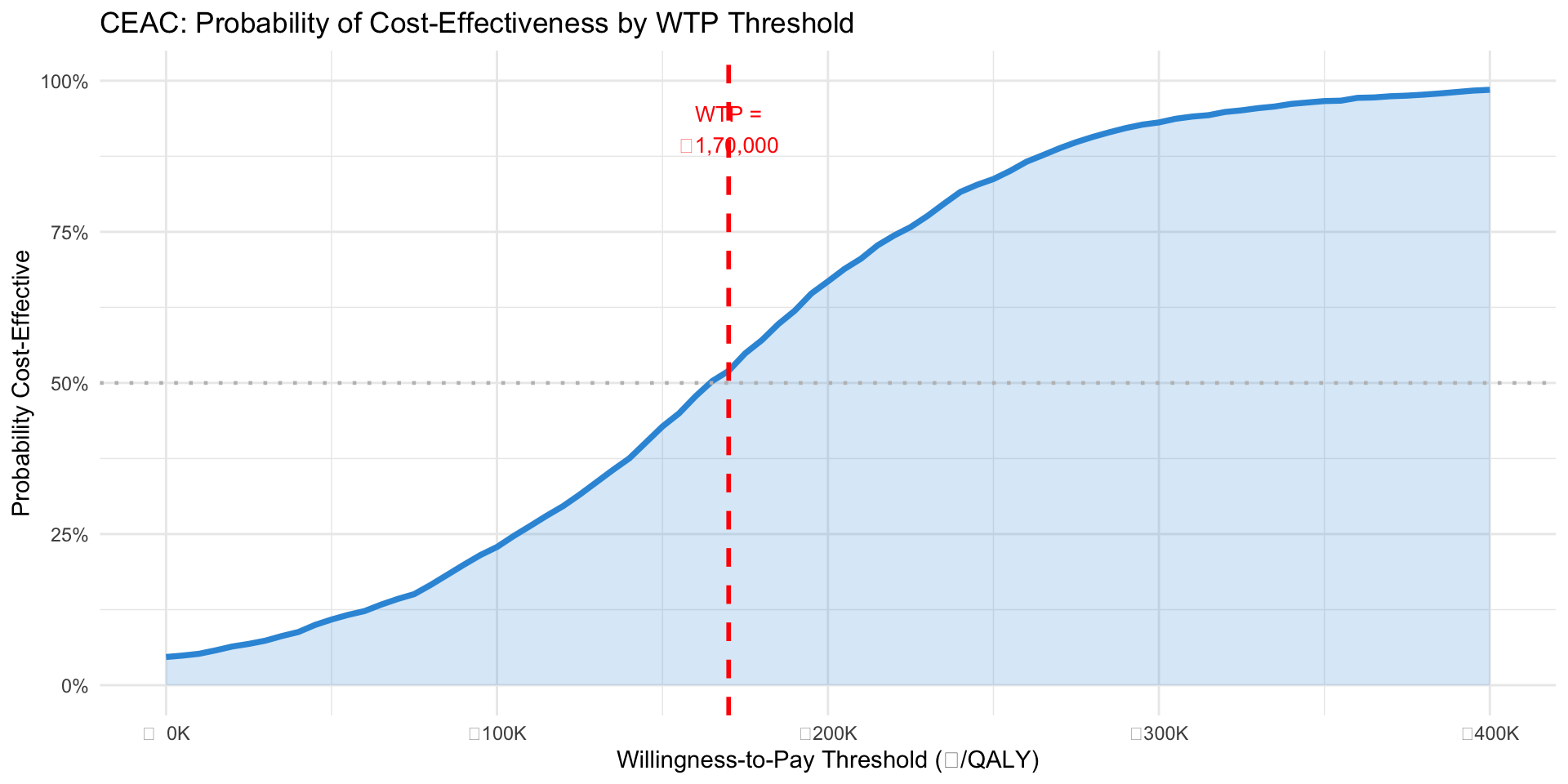
Figure 3: Probability that trastuzumab is cost-effective at each WTP threshold
At ₹1,70,000/QALY: ~60% probability trastuzumab is cost-effective
At ₹2,50,000/QALY: ~80% probability